Source: author's recreation from the technical guide to the Civil Service People Survey (Cabinet Office, 2014)
The Civil Service People Survey’s analytical framework is based around the concept of “employee engagement”. Historically survey outputs (including organisational and team reports) used to illustrate how different themes within the survey were ‘drivers’ of employee engagement.
Over the years this focus has been somewhat lost, initially through a methodology change by a contractor switching to simple question-level correlation and more recently with a change in the reporting infrastructure that made it more operationally difficult to implement.
This article recaps the historic analytical framework, replicates the analysis (as far as is possible) and explains how this has been used in the presentation of results on this website. For a simpler guide that summarises only the framework and outputs of the driver analysis please read the driver analysis guide instead.
An analytical framework for employee engagement
The Cabinet Office (2014, p13) defines ‘employee engagement’ as follows:
Employee engagement is a workplace approach designed to ensure that employees are committed to their organisation’s goals and values, motivated to contribute to organisational success, and are able at the same time to enhance their own sense of well-being.
The survey’s analytical framework posits that “by taking action to improve our people’s experiences of work we increase levels of employee engagement which raises performance and enhances wellbeing” (Cabinet Office 2014, p12), see Figure 1.
The People Survey operationalises its measurement of employee engagement through and ‘engagement index’ made up of five questions that measure levels of “pride, advocacy, attachment, inspiration and motivation” (Cabinet Office 2014) (ADD LINK TO EE ARTICLE). The ‘experiences of work’ described in the analytical framework relate to the nine themes of the survey’s core questionnaire that precede the five questions of the engagement index.
Historic driver analysis
The questions in the core questionnaire preceding the engagement index are grouped based on a factor analysis1 of the 2009 People Survey results, providing the nine core survey themes: my work; organisational objectives and purpose; my manager; my team; learning and development; inclusion and fair treatment; resources and workload; pay and benefits; and, leadership and managing change.
From 2009 to 2018 the PDF-reports of People Survey results for organisations and teams included the results ‘driver analysis’ that reported the relationship between the engagement index and the nine main themes of the survey. The driver analysis was presented in three places within the PDF reports: on the front page of the report (Figure 2 (a)), a dedicated summary table (Figure 2!), and alongside the presentation of the question results for each theme (Figure 2 (c)).

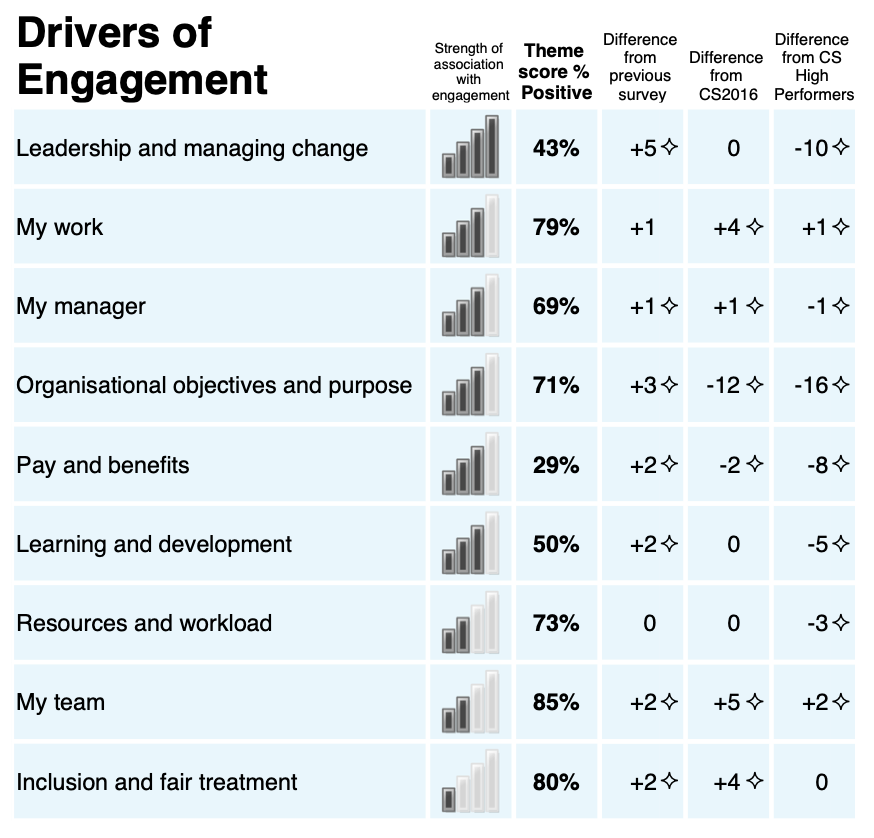
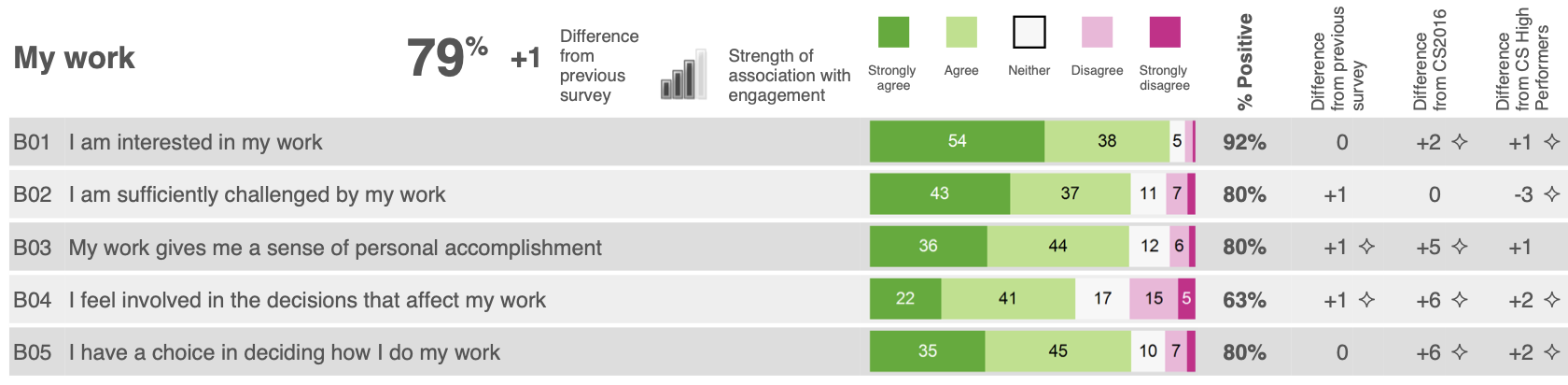
Source: Cabinet Office (2016)
The driver analysis was based on a linear regression model of the ‘factor scores’ against the engagement index to determine the ‘strength of association’ between each theme and levels of employee engagement. This analysis was run for each organisation with at least 100 respondents, it was also run in all sub-units (below the overall organisation level) with at least 150 respondents, smaller units inherited the analysis results of their parent unit/organisation. The beta coefficients from the regression analysis were then used to assign one of five icons that illustrated the strength of association between a theme and the engagement index. The icons used mimicked the icons used by mobile phones to indicate signal strength: an icon with 4 full bars indicated a strong relationship and an icon with 0 full bars indicated no statistically significant relationship had been identified.
In 2009 the linear regression analysis was based on the observed mean scores of the questions making up the engagement index and each of the nine themes. However, this methodology was flawed owing to multicollinearity between the theme scores as it results in bizarre outputs suggesting that levels of employee engagement are negatively related to certain themes. In 2010 I instituted a change to the methodology to base the analysis on ‘factor scores’ to removed this multicollinearity.
In 2018, after I had stopped being directly involved in the People Survey, the contractor instituted a methodological change to focus on question-level correlation and regression analysis. In 2020, a change in contractor resulted in a switch to a new online-only reporting platform, ending the production of organisation- and team-level PDF reports. This new platform also significantly increase the level of effort and complexity required to re-implement the historic approach to driver analysis.
Recreating the driver analysis
Personally, I believe abandoning driver analysis has a negative impact on interpreting the results of the People Survey as it hampers people from understanding where they can best focus action on improving results.
This website is based only on the publicly available People Survey data published by the Cabinet Office, therefore it is not possible to directly replicate the historic driver analysis since this was based on the individual level People Survey responses. Instead, in this article I’ve used the published organisation scores as the source data to recreate the driver analysis, providing a dataset with 1,652 observations.
Demonstrating multicollinearity
I mentioned above instituting a change in 2010 to conduct the driver analysis using ‘factor scores’ that are output from the factor analysis used to group the survey questions into themes. This is due to multicollinearity in the data if we run a regression analysis between the engagement index and the simple percent positive scores for each theme (the theme scores published in the data, including internal reporting).
But what does this mean in practice? Multicollinearity means that there is a high degree of correlation between the predictive variable in the regression model meaning it is not easy to determine the true relationship between a given predictive variable and the outcome variable.
In practice, we can see that the multicollinearity produces coefficients that do not make sense. Table 1 shows the results of a linear regression of the engagement index against the nine theme scores using the organisation scores from 2009 to 2024. We can see in this tables some strange results, namely the presence of negative coefficients for the ‘my manager’ and ‘my team’ themes. This seems counter-intuitive as it would suggest having poor ratings of your manager and immediate colleagues would lead to higher levels of employee engagement, and goes against the vast majority of literature about employee motivation. The coefficient of the ‘pay and benefits’ theme is also not statistically significant. The upper triangle of the correlation matrix shown in Figure 5 also provides a visual representation of the multicollinearity indicating the high degree of correlation between each of the theme scores.
Code
csps_orgs <- arrow::read_parquet(
here::here(
"../csps-data/data/02-organisations/csps_organisations_2009-2024_5b58c24b.parquet"
)
)
org_ee_tm_scores <- csps_orgs |>
dplyr::filter(grepl("^1.", uid_qm_num)) |>
dplyr::mutate(uid_qm_txt = gsub("^000.", "", uid_qm_txt)) |>
dplyr::select(uid_org_txt, year, uid_qm_txt, value) |>
tidyr::pivot_wider(names_from = uid_qm_txt, values_from = value)
org_simple_reg <- lm(
engagement_index ~ my_work + objectives_purpose + my_manager + my_team +
learning_development + inclusion_treatment + resources_workload +
pay_benefits + leadership_change,
data = org_ee_tm_scores
)
org_simple_fit <- broom::glance(org_simple_reg)
org_simple_coefs <- broom::tidy(org_simple_reg)
org_simple_coefs |>
dplyr::mutate(
term = dplyr::case_match(
term,
"my_work" ~ "My work",
"objectives_purpose" ~ "Organisational objectives and purpose",
"my_manager" ~ "My manager",
"my_team" ~ "My team",
"learning_development" ~ "Learning and development",
"inclusion_treatment" ~ "Inclusion and fair treatment",
"resources_workload" ~ "Resources and workload",
"pay_benefits" ~ "Pay benefits",
"leadership_change" ~ "Leadership and managing change",
.default = term
),
across(c(estimate, std.error), scales::number_format(0.001)),
p.value = scales::pvalue(p.value)
) |>
dplyr::select(-statistic) |>
knitr::kable(
col.names = c("", "Coefficient", "Std Error", "p-value"),
align = "lrrr"
)
tibble::tribble(
~statistic, ~value,
"R<sup>2</sup>", scales::number(org_simple_fit$r.squared, 0.001),
"Adjusted R<sup>2</sup>", scales::number(org_simple_fit$adj.r.squared, 0.001),
"F-statistic", scales::comma(org_simple_fit$statistic, 0.1),
"p-value", scales::pvalue(org_simple_fit$p.value),
"df", paste(org_simple_fit$df, scales::comma(org_simple_fit$df.residual), sep = "; "),
"Observations", scales::comma(org_simple_fit$nobs)
) |>
knitr::kable(
col.names = NULL,
align = "lr"
)| Coefficient | Std Error | p-value | |
|---|---|---|---|
| (Intercept) | 0.991 | 1.855 | 0.593 |
| My work | 0.406 | 0.021 | <0.001 |
| Organisational objectives and purpose | 0.110 | 0.014 | <0.001 |
| My manager | -0.100 | 0.022 | <0.001 |
| My team | -0.055 | 0.026 | 0.036 |
| Learning and development | 0.036 | 0.014 | 0.011 |
| Inclusion and fair treatment | 0.142 | 0.030 | <0.001 |
| Resources and workload | 0.106 | 0.021 | <0.001 |
| Pay benefits | 0.014 | 0.008 | 0.061 |
| Leadership and managing change | 0.234 | 0.013 | <0.001 |
| R2 | 0.830 |
| Adjusted R2 | 0.829 |
| F-statistic | 893.0 |
| p-value | <0.001 |
| df | 9; 1,642 |
| Observations | 1,652 |
A brief introduction to factor analysis
Factor analysis is a statistical technique for ‘dimension reduction’, it uses the correlations between variables to detect a smaller number of latent (hidden) variables that lie behind the observed scores and results. The use of factor analysis in social survey analysis posits that these unseen latent variables influence how we respond to survey questions (the observed variables). For example and as seen in Figure 4, the question “I have a choice in deciding how I do my work” is related to both the underlying ‘my work’ factor and the ‘my manager’ factor. This dual loading is somewhat intuitive since having autonomy in your job is both a feature of the work you do and dependent on being given that autonomy by your supervisor.
This connection between a question and multiple latent factors is a key reason for the multicollinearity demonstrated in the previous section. Figure 3 presents a simplified way to think about the difference between theme scores and factor scores. The theme scores published in People Survey outputs are calculated as the percent positive response across the theme’s constituent questions. While the questions have a strong relationship with the theme they have been grouped into they also have relationships with other factors (and thus theme scores), in essence creating an overlap between the theme scores (or in technical terms correlation between the theme scores). The factor scores however can be designed (by using what’s called an ‘orthogonal rotation’) to have only a minimal correlation between each other and thus are a more ‘clean’ measure of the underlying latent variable/concept.
Source: based on the technical guide to the Civil Service People Survey (Cabinet Office, 2014)
The factor analysis model
The input to the factor analysis are the scores for the questions that precede the engagement index in the questionnaire2. As discussed above, the individual level data is not available and so the organisation scores for these questions from 2009 to 2024 have been used as the source data.
Since the People Survey continues to use 9 themes in its structuring of the questionnaire an exploratory factor analysis that extracts 9 factors from the data. As we can see in Table 2 (a) this 9 factor model explains 85% of the variation in the question scores. Table 2 (b) shows that the first 7 factors all have an eigenvalue of greater than 1 (a standard cut-off value for determining which factors to consider in further analysis), and cumulatively these 7 factors account for 81% of the variation. Factors 8 and 9 have eigenvalues of slightly less than 1 but each still account for around 2% of the variation in the dataset, so we’ll review the factor loadings before determining whether to retain or ignore these factors.
Code
qm_input_org <- csps_orgs |>
dplyr::filter(grepl("^2.0", uid_qm_num)) |>
dplyr::add_count(uid_org_txt, uid_qm_num) |>
dplyr::filter(n == max(n), .by = uid_org_txt) |>
dplyr::filter(
!(uid_qm_txt %in% c(
"obj.understanding_purpose", "mgr.poor_performance",
"rwk.clear_expectations", "lmc.organisation_managed_well",
"pay.aware_benefits", "pay.money_worries"
))
) |>
dplyr::select(uid_org_txt, year, name = uid_qm_txt, value) |>
tidyr::pivot_wider(names_from = name, values_from = value)
set.seed(20251712)
fa_model_org <- factanal(
x = dplyr::select(qm_input_org, where(is.numeric), -year),
factors = 9,
scores = "regression", rotation = "varimax"
)
fa_loadings_org <- broom::tidy(fa_model_org) |>
dplyr::mutate(
theme = gsub("(^[a-z]{3})\\..*", "\\1", variable),
.before = variable
)
fa_summary_org <- fa_loadings_org |>
dplyr::select(fl1:fl9) |>
tidyr::pivot_longer(
cols = everything(), names_to = "factor", values_to = "value"
) |>
dplyr::summarise(
eigenvalue = sum(value ^2),
.by = factor
) |>
dplyr::mutate(
factor = as.integer(gsub(".*(\\d)", "\\1", factor)),
prop_var = eigenvalue/nrow(fa_loadings_org),
cuml_var = cumsum(prop_var)
) |>
dplyr::mutate(
eigenvalue = scales::number(eigenvalue, accuracy = 0.001),
prop_var = scales::percent(prop_var, accuracy = 0.1),
cuml_var = scales::percent(cuml_var, accuracy = 0.1)
)
fa_fit_org <- broom::glance(fa_model_org)
tibble::tribble(
~statistic, ~value,
"Number of factors", as.character(fa_fit_org$n.factors),
"Method", "Maximum-likelihood estimation",
"Rotation", "Varimax",
"Variance explained", scales::percent(fa_fit_org$total.variance, 0.1),
"\u03C7<sup>2</sup> (Chi-square) statistic", scales::comma(fa_fit_org$statistic, 0.1),
"p-value", scales::pvalue(fa_fit_org$p.value),
"df", scales::comma(fa_fit_org$statistic),
"Observations", scales::comma(fa_fit_org$nobs)
) |>
knitr::kable(
col.names = NULL,
align = "lr"
)
knitr::kable(
fa_summary_org,
col.names = c(
"Factor", "Eigenvalue", "Variance explained", "Cumulative variance"
),
align = "crrr"
)| Number of factors | 9 |
| Method | Maximum-likelihood estimation |
| Rotation | Varimax |
| Variance explained | 85.0% |
| χ2 (Chi-square) statistic | 13,117.8 |
| p-value | <0.001 |
| df | 13,118 |
| Observations | 1,652 |
| Factor | Eigenvalue | Variance explained | Cumulative variance |
|---|---|---|---|
| 1 | 11.523 | 25.6% | 25.6% |
| 2 | 7.662 | 17.0% | 42.6% |
| 3 | 5.305 | 11.8% | 54.4% |
| 4 | 4.335 | 9.6% | 64.1% |
| 5 | 3.346 | 7.4% | 71.5% |
| 6 | 2.684 | 6.0% | 77.5% |
| 7 | 1.583 | 3.5% | 81.0% |
| 8 | 0.939 | 2.1% | 83.1% |
| 9 | 0.874 | 1.9% | 85.0% |
Figure 4 illustrates the uniqueness scores and factor loadings of each of the 45 questions that were included in the factor analysis model.
The uniqueness score illustrates the amount of variation within the given question that is not covered by the factor model. Some questions in each of the ‘resources and workload’, ‘learning and development’, ‘inclusion and fair treatment’, and ‘my work’ themes all have uniqueness levels greater than or equal to 0.25 (i.e. more than 25% of the variance remains unexplained). It is not possible to know whether this is due to use of organisation score data rather than individual-level response or due to some other reason.
The factor loadings illustrate the correlation between each question and each of the 9 factors in the model. As can be observed in Figure 4:
- Factor 1 has strong, moderate and weak correlation with many questions in the survey, its strongest correlations are with questions in the ‘my manager’ theme but it also has several strong and moderate correlations with questions in the ‘my team’ and ‘inclusion and fair treatment’ themes than others.
- Factor 2 has strong correlations with the questions in the ‘leadership and managing change’ theme, but as with factor 1 it has weak and moderate correlations with many questions across the survey.
- Factor 3 has moderate strong correlations with the questions in the ‘my work’ theme as well as a couple of individual questions in other themes, including the ‘learning and development’ and ‘resources and workload’ themes.
- Factor 4 has strong and moderate correlations with the questions in the ‘resources and workload’ theme.
- Factor 5 has very strong correlations with the questions in the ‘pay and benefits’ theme and only very weak correlations with the other questions in the survey. Similarly the questions in the ‘pay and benefits’ theme only have notable correlations with this factor, they have no or very weak correlation with other factors.
- Factor 6 has strong correlations with questions in the ‘organisational objectives and purpose’ theme as well as moderate correlation with two questions relating to objectives from the ‘my manager’ and ‘resources and workload’ themes.
- Factor 7 has moderate correlations with the career-related questions in the ‘learning and development’ theme and weaker correlations with the learning activities-related questions in that theme. There is only limited correlation with other questions in the survey.
- Factor 8 has moderate correlations with two of the questions in the ‘my team’ theme. There is a weak correlation with the third question in the ‘my team’ theme. All three questions in the ‘my team’ theme have similar or stronger correlation with factor 1.
- Factor 9 has weak correlations with three questions, two questions in the ‘my manager’ theme relating to receiving feedback and the question in the ‘resources and workload’ theme on having clear work objectives. It has a weak negative correlation with the question in the ‘my work’ theme on whether an individual feels they have a choice in how they do their work.
Code
library(ggplot2)
gdf_factor_loadings <- fa_loadings_org |>
dplyr::mutate(y = dplyr::row_number()) |>
dplyr::select(-theme, -variable, -uniqueness) |>
tidyr::pivot_longer(
cols = -y,
names_to = "factor",
values_to = "loading"
) |>
dplyr::mutate(
x = as.integer(gsub(".*(\\d)$", "\\1", factor)),
alpha = abs(loading) <= 0.3
)
gdf_uniqueness <- fa_loadings_org |>
dplyr::mutate(y = dplyr::row_number()) |>
dplyr::select(y, uniqueness)
gdf_theme_borders <- fa_loadings_org |>
dplyr::select(theme) |>
dplyr::mutate(
y = dplyr::row_number() - 0.5,
same_theme = tidyr::replace_na(theme == dplyr::lag(theme), TRUE)
) |>
dplyr::filter(!same_theme)
gdf_question_labels <- fa_loadings_org |>
dplyr::select(variable) |>
dplyr::mutate(y = dplyr::row_number())
loadings_plot <- ggplot(gdf_factor_loadings, aes(x = x, y = y)) +
geom_rect(
data = gdf_uniqueness,
aes(x = 0, fill = uniqueness), colour = NA, width = 0.9, height = 1
) +
scale_fill_distiller(
palette = "PuBu", direction = 1,
guide = guide_colorbar(title = "Uniqueness", order = 1)
) +
ggnewscale::new_scale_fill() +
geom_rect(
aes(fill = loading, alpha = alpha), colour = NA, width = 0.9, height = 1
) +
geom_hline(
yintercept = seq(1.5, 44.5, 1), colour = "#e0e0e0", linewidth = 0.2
) +
geom_hline(
data = gdf_theme_borders,
mapping = aes(yintercept = y),
colour = "#6f6f6f", linewidth = 0.3
) +
geom_text(
aes(
label = scales::number(loading, 0.01),
colour = abs(round(loading, 2)) > 0.75
),
size = 3, family = "IBM Plex Sans", show.legend = FALSE
) +
geom_text(
data = gdf_uniqueness,
aes(
x= 0,
label = scales::number(uniqueness, 0.01),
colour = abs(round(uniqueness, 2)) >= 0.25
),
size = 3.25, family = "IBM Plex Sans", show.legend = FALSE
) +
geom_text(
data = gdf_question_labels,
aes(label = variable, x = -0.6),
size = 3.25, hjust = 1, family = "IBM Plex Sans", colour = "#393939"
) +
scale_fill_gradient2(
low = "#D01C8B", mid = "#F7F7F7", high = "#4DAC26",
midpoint = 0,
guide = guide_colorbar(
title = "Loading", order = 2
)
) +
scale_alpha_manual(
values = c(`FALSE` = 1, `TRUE` = 0.4),
guide = guide_none()
) +
scale_colour_manual(
values = c(`TRUE` = "#ffffff", `FALSE` = "#393939"),
guide = guide_none()
) +
scale_y_reverse(
expand = expansion(),
labels = NULL
) +
scale_x_continuous(
breaks = 0:9,
labels = c("Uniqueness", paste("Factor", 1:9)),
expand = expansion(add = c(2.25, 0)),
position = "top"
) +
labs(x = NULL, y = NULL) +
theme_minimal(
base_size = 10, base_family = "IBM Plex Sans"
) +
theme(
text = element_text(colour = "#393939"),
axis.text.x = element_text(size = 10),
panel.grid = element_blank()
)
inlinesvg::inline_svg_plot(
loadings_plot,
here::here("partials/plots/fa_loadings_plot.svg"),
width = 1200, height = 1000, overwrite = TRUE,
source_note = "Note: loadings between 0 and ±0.3 are shown at 40% transparency.",
web_fonts = svglite::fonts_as_import("IBM Plex Sans")
)
## /Users/matt/code/csps-explorer/partials/plots/fa_loadings_plot.svgNote: loadings between 0 and ±0.3 are shown at 40% transparency.
The relationship between survey themes and factors
The factor analysis model can also produce scores for each factor, providing an estimate for each observation of its notional score on each of the latent variables if they were ‘real’ variables. These scores can then be used in further analysis.
Let’s first look at the correlation of these factor scores with the original theme scores (the simple percent positive response to the questions in each group) as this should further aid our understanding of what each factor represents.
Figure 5 shows the correlation matrix of the engagement index and theme scores with the factor scores, you can see in the upper triangle the high levels of correlation most themes have with each other while in the lower triangle you can see the very low level of correlation between each of the factor scores. Focussing on the square showing the correlations of the theme scores against the factor scores we see patterns that are similar to those in the factor loadings (Figure 4):
- Factor 1 has a very strong correlation with the ‘my manager’ theme score, as well as moderate correlations with the ‘my work’, ‘my team’ and ‘inclusion and fair treatment’ themes. Let’s call this theme ‘management’ as it relates both to respondents’ direct relationship with their direct supervisor but also other issues relating to team and working culture that managers are responsible.
- Factor 2 has a strong correlation with the ‘leadership and managing change’ theme and only weak correlations with the other theme scores, so let’s call this factor ‘leadership’.
- Factor 3 has a strong correlation with the ‘my work’ theme and only weak correlations with the other theme scores, so let’s call this factor ‘work’.
- Factor 4 has a strong correlation with the ‘resources and workload’ theme and only weak correlations with the other theme scores. Let’s call this factor ‘workload’ since in the factor structure it loads more strongly on the workload related questions within the ‘resources and workload’ theme.
- Factor 5 has a very strong correlation with the ‘pay and benefits’ theme and only very weak corelation with the other theme scores, so let’s call this factor ‘pay’.
- Factor 6 has a very strong correlation with the ‘organisational objectives and purpose’ theme. Since this theme has moderate loading with other questions relating to an individual’s work objectives, let’s call this theme ‘objectives’.
- Factor 7 has a moderate correlation with the ‘learning and development’ theme and is only weakly correlated with the other theme scores. In the factor structure this factor loads more strongly on the questions relating to career development and since the questions relating to learning activities have correlations with other factors let’s call this one ‘career’.
- Factor 8 has a moderate correlation with the ‘my team’ theme and only minimal correlation with the other theme scores. Even though the questions in the ‘my team’ theme have strong correlation with factor 1 than factor 8 let’s still call this ‘teamwork’ since it does not correlate with any other measures in the survey.
- Factor 9 has no strong or moderate correlation with any of the nine main theme scores. Recalling from the factor structure that its strongest loadings are on questions relating to feedback and work objectives let’s call this factor ‘feedback’.
Code
fa_scores_org <- org_ee_tm_scores |>
dplyr::bind_cols(broom::augment(fa_model_org)) |>
dplyr::select(-.rownames) |>
dplyr::rename(
f1_management = .fs1,
f2_leadership = .fs2,
f3_work = .fs3,
f4_workload = .fs4,
f5_pay = .fs5,
f6_objectives = .fs6,
f7_career = .fs7,
f8_teamwork = .fs8,
f9_feedback = .fs9
)
tm_fs_corr <- fa_scores_org |>
dplyr::select(engagement_index:f9_feedback) |>
as.matrix() |>
Hmisc::rcorr()
tm_fs_cor_tidy <- broom::tidy(tm_fs_corr) |>
dplyr::mutate(
across(
c(column1, column2),
~factor(.x, levels = names(fa_scores_org)[c(-1, -2)])
),
alpha = !(p.value < 0.05),
)
tm_fs_plot <- ggplot(tm_fs_cor_tidy, aes(x = column2, y = column1)) +
geom_rect(
fill = "#ffffff", width = 1, height = 1
) +
geom_rect(
aes(fill = estimate, alpha = alpha), colour = "#e0e0e0",
width = 1, height = 1
) +
geom_hline(
yintercept = 9.5, linewidth = 0.3, colour = "#6f6f6f", linetype = "dashed"
) +
geom_vline(
xintercept = 10.5, linewidth = 0.3, colour = "#6f6f6f", linetype = "dashed"
) +
geom_text(
aes(label = scales::number(estimate, 0.01), colour = round(estimate,2) > 0.75),
size = 3, family = "IBM Plex Sans"
) +
scale_fill_gradient2(
low = "#D01C8B", mid = "#F7F7F7", high = "#4DAC26",
midpoint = 0,
guide = guide_colorbar(
title = NULL
)
) +
scale_alpha_manual(
values = c(`TRUE` = 0, `FALSE` = 1),
na.value = 0,
guide = guide_none()
) +
scale_colour_manual(
values = c(`TRUE` = "#ffffff", `FALSE` = "#393939"),
guide = guide_none()
) +
scale_x_discrete(
position = "top",
expand = expansion(add = 0.75),
drop = FALSE
) +
scale_y_discrete(
limits = rev,
expand = expansion(add = 0.75, 0),
drop = FALSE
) +
labs(y = NULL, x = NULL) +
coord_fixed() +
theme_minimal(base_family = "IBM Plex Sans", base_size = 10) +
theme(
text = element_text(colour = "#393939"),
axis.text.x = element_text(angle = 45, hjust = 0, vjust = 0),
panel.grid.major.x = element_line(
colour = "#e0e0e0", linewidth = 0.2
),
panel.grid.major.y = element_blank()
)
inlinesvg::inline_svg_plot(
tm_fs_plot, here::here("partials/plots/tm_fs_correlation.svg"),
width = 950, height = 840, overwrite = TRUE,
source_note = "Note: correlations that are not statistically significant (p > 0.05) have a white background.",
web_fonts = svglite::fonts_as_import("IBM Plex Sans")
)
## /Users/matt/code/csps-explorer/partials/plots/tm_fs_correlation.svgNote: correlations that are not statistically significant (p > 0.05) have a white background.
Cross-sectional analysis, longitudinal analysis or both
Now that factor scores have been calculated, new regression models can be conducted of these scores against the engagement index instead of the theme scores. The original driver analysis based on individual level data, and the theme scores analysis above are both ‘cross-sectional’, that is, they are regression models based using data for a given year. As the survey is anonymous, if using individual level data then this is the only available method as there is no mechanism for linking individuals’ responses over time.
However, the data we are using is organisation level data, which means we can link data over time. This means that in addition to a ‘cross-sectional’ analysis that looks at how the factor scores relate to the engagement index, we can also calculate the change in factor scores and change in engagement index, and use that as input for a regression model.
A cross-sectional driver analysis model
Firstly, we’ll look at the cross-sectional model, this shows which factors (and thus associated themes) have a stronger relationshup with the engagement index than others.
Before discussing the model results, it is worth noting that the R2 for the factor scores model is somewhat higher (0.843) than that of the model using theme scores (0.830). This suggests that using the factor scores provides a better way of explaining the variation in the engagement index than the theme scores.
Table 3 shows the standardised, or beta, coefficients from the model as the engagement index and factor scores operate on different scales3.
The ‘leadership’ factor and the ‘work’ factor have the strongest association with the engagement index (coefficients of 0.519 and 0.485 respectively). These are followed by the ‘management’ factor (0.338), the ‘workload’ and ‘objectives’ factor (0.256 and 0.240 respectively), and then ‘pay’ and ‘career’ factors (0.157 and 0.151 respectively). The ‘teamwork’ factor has only a limited effect on the engagement index (0.084), while the ‘feedback’ factor does not have a statsitically significant effect.
Code
drivers_fa <- lm(
engagement_index ~ f1_management + f2_leadership + f3_work +
f4_workload + f5_pay + f6_objectives + f7_career + f8_teamwork +
f9_feedback,
data = fa_scores_org
)
drivers_beta <- lm.beta::lm.beta(drivers_fa)
drivers_fit <- broom::glance(drivers_fa)
drivers_coefs <- broom::tidy(drivers_beta)
drivers_coefs |>
dplyr::mutate(
term = dplyr::case_match(
term,
"f1_management" ~ "Factor 1: Management",
"f2_leadership" ~ "Factor 2: Leadership",
"f3_work" ~ "Factor 3: My work",
"f4_workload" ~ "Factor 4: Workload",
"f5_pay" ~ "Factor 5: Pay",
"f6_objectives" ~ "Factor 6: Objectives",
"f7_career" ~ "Factor 7: Career",
"f8_teamwork" ~ "Factor 8: Teamwork",
"f9_feedback" ~ "Factor 9: Feedback",
.default = term
),
across(c(std_estimate, std.error), scales::number_format(0.001)),
p.value = scales::pvalue(p.value)
) |>
dplyr::select(term, std_estimate, std.error, p.value) |>
knitr::kable(
col.names = c("", "Beta coefficient", "Std Error", "p-value"),
align = "lrrr"
)
tibble::tribble(
~statistic, ~value,
"R<sup>2</sup>", scales::number(drivers_fit$r.squared, 0.001),
"Adjusted R<sup>2</sup>", scales::number(drivers_fit$adj.r.squared, 0.001),
"F-statistic", scales::comma(drivers_fit$statistic, 0.1),
"p-value", scales::pvalue(drivers_fit$p.value),
"df", paste(drivers_fit$df, scales::comma(drivers_fit$df.residual), sep = "; "),
"Observations", scales::comma(drivers_fit$nobs)
) |>
knitr::kable(
col.names = NULL,
align = "lr"
)| Beta coefficient | Std Error | p-value | |
|---|---|---|---|
| (Intercept) | NA | 0.075 | <0.001 |
| Factor 1: Management | 0.338 | 0.076 | <0.001 |
| Factor 2: Leadership | 0.519 | 0.076 | <0.001 |
| Factor 3: My work | 0.485 | 0.078 | <0.001 |
| Factor 4: Workload | 0.256 | 0.079 | <0.001 |
| Factor 5: Pay | 0.157 | 0.076 | <0.001 |
| Factor 6: Objectives | 0.240 | 0.076 | <0.001 |
| Factor 7: Career | 0.151 | 0.083 | <0.001 |
| Factor 8: Teamwork | 0.084 | 0.076 | <0.001 |
| Factor 9: Feedback | -0.013 | 0.080 | 0.201 |
| R2 | 0.843 |
| Adjusted R2 | 0.842 |
| F-statistic | 978.6 |
| p-value | <0.001 |
| df | 9; 1,642 |
| Observations | 1,652 |
A longitudinal driver analysis model
Table 4 shows the results of a linear regression model where the input data is the change in the engagement index and the change in factor scores and the year before. That is, each row in the input data shows the change in engagement index for a given organisation between two years (e.g. 2009 and 2010, or 2023 and 2024, etc) and the changes in the factor scores for those years. As with the cross-sectional analysis (Table 3) the outputs show the standardised, or beta, coefficients from the regression model.
The ‘leadership’ and ‘management’ factors have the strongest coefficients (0.588 and 0.530 respectively), followed by the ‘work’ factor (0.401). These are followed by the ‘workload’ and ‘objectives’ factors (0.331 and 0.309 respectively), the ‘career’ and ‘pay’ factors (0.293 and 0.226 respectively), and the ‘teamwork’ factor (0.141). Unlike the cross-sectional analysis the ‘feedback’ factor does have a statistically significant effect (p=0.03) but the p-value of other coefficients is much stronger (all p<0.001), and the coefficient its self is relatively weak (-0.03 compared to 0.141 to 0.588).
Compared the the cross-sectional analysis, for all factors the coefficients are stronger in the longitudinal model, however the overall R2 is slightly less for the longitutdinal model than the cross-sectional model (0.800 for the longitudional model compared to 0.843 for the cross-sectional model).
Code
org_chains <- readr::read_csv(
here::here("../csps-data/proc/99-testing/99-org-chains.csv")
)
## Rows: 11230 Columns: 2
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): trend_group, org_yr_id
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
trend_groups_latest <- fa_scores_org |>
dplyr::distinct(year, uid_org_txt) |>
dplyr::mutate(org_yr_id = paste(year, uid_org_txt, sep = "_")) |>
dplyr::full_join(org_chains, by = "org_yr_id") |>
dplyr::mutate(trend_group_root = gsub("^\\d+", "", trend_group)) |>
dplyr::arrange(desc(trend_group), -year, trend_group_root) |>
dplyr::distinct(uid_org_txt, trend_group_root, .keep_all = TRUE) |>
dplyr::distinct(trend_group) |>
dplyr::pull(trend_group) |>
sort()
org_chains_latest <- org_chains |>
dplyr::filter(trend_group %in% trend_groups_latest)
fa_scores_chg <- fa_scores_org |>
dplyr::mutate(org_yr_id = paste(year, uid_org_txt, sep = "_")) |>
dplyr::filter(org_yr_id %in% org_chains_latest$org_yr_id) |>
dplyr::left_join(org_chains_latest, by = "org_yr_id") |>
tidyr::pivot_longer(
cols = c(-uid_org_txt, -year, -org_yr_id, -trend_group),
names_to = "var"
) |>
dplyr::filter(var == "engagement_index" | substr(var, 1, 1) == "f") |>
dplyr::arrange(trend_group, var, year) |>
dplyr::mutate(
diff = value - dplyr::lag(value),
.by = c(trend_group, var)
) |>
dplyr::filter(!is.na(diff)) |>
dplyr::select(trend_group, year, var, diff) |>
tidyr::pivot_wider(names_from = var, values_from = diff)
drivers_fa_chg <- lm(
engagement_index ~ f1_management + f2_leadership + f3_work +
f4_workload + f5_pay + f6_objectives + f7_career + f8_teamwork +
f9_feedback,
data = fa_scores_chg
)
drivers_chg_beta <- lm.beta::lm.beta(drivers_fa_chg)
drivers_chg_fit <- broom::glance(drivers_chg_beta)
## Warning: The `glance()` method for objects of class `lm.beta` is not maintained by the broom team, and is only supported through the `lm` tidier method. Please be cautious in interpreting and reporting broom output.
##
## This warning is displayed once per session.
drivers_chg_coefs <- broom::tidy(drivers_chg_beta)
drivers_chg_coefs |>
dplyr::mutate(
term = dplyr::case_match(
term,
"f1_management" ~ "Factor 1: Management",
"f2_leadership" ~ "Factor 2: Leadership",
"f3_work" ~ "Factor 3: My work",
"f4_workload" ~ "Factor 4: Workload",
"f5_pay" ~ "Factor 5: Pay",
"f6_objectives" ~ "Factor 6: Objectives",
"f7_career" ~ "Factor 7: Career",
"f8_teamwork" ~ "Factor 8: Teamwork",
"f9_feedback" ~ "Factor 9: Feedback",
.default = term
),
across(c(std_estimate, std.error), scales::number_format(0.001)),
p.value = scales::pvalue(p.value)
) |>
dplyr::select(term, std_estimate, std.error, p.value) |>
knitr::kable(
col.names = c("", "Beta coefficient", "Std Error", "p-value"),
align = "lrrr"
)
tibble::tribble(
~statistic, ~value,
"R<sup>2</sup>", scales::number(drivers_chg_fit$r.squared, 0.001),
"Adjusted R<sup>2</sup>", scales::number(drivers_chg_fit$adj.r.squared, 0.001),
"F-statistic", scales::comma(drivers_chg_fit$statistic, 0.1),
"p-value", scales::pvalue(drivers_chg_fit$p.value),
"df", paste(drivers_fit$df, scales::comma(drivers_chg_fit$df.residual), sep = "; "),
"Observations", scales::comma(drivers_chg_fit$nobs)
) |>
knitr::kable(
col.names = NULL,
align = "lr"
)| Beta coefficient | Std Error | p-value | |
|---|---|---|---|
| (Intercept) | NA | 0.043 | 0.142 |
| Factor 1: Management | 0.530 | 0.090 | <0.001 |
| Factor 2: Leadership | 0.588 | 0.077 | <0.001 |
| Factor 3: My work | 0.401 | 0.085 | <0.001 |
| Factor 4: Workload | 0.331 | 0.077 | <0.001 |
| Factor 5: Pay | 0.226 | 0.081 | <0.001 |
| Factor 6: Objectives | 0.309 | 0.068 | <0.001 |
| Factor 7: Career | 0.293 | 0.078 | <0.001 |
| Factor 8: Teamwork | 0.141 | 0.049 | <0.001 |
| Factor 9: Feedback | -0.028 | 0.077 | 0.028 |
| R2 | 0.800 |
| Adjusted R2 | 0.799 |
| F-statistic | 666.4 |
| p-value | <0.001 |
| df | 9; 1,499 |
| Observations | 1,509 |
Reporting the driver analysis
As discussed above the previous driver analysis had used a set of icons that mimicked the icons used by mobile phones to indicate signal strength. I believe this continues to be a useful visual metaphor/semiotic for demonstrating the regression coefficients, and have included a similar set of updated signal strength icons in the results section of this website (e.g. the Civil Service benchmark and individual organisation results pages).
Since the driver analysis is based on a regression model using factor scores the specific values of the coefficients are not easily interpretted, even by professional analysts. That does not mean the coefficients are irrelevant, they tell us that the ‘leadership’ factor has a notably stronger impact on the engagement index than the ‘pay’ factor, but presenting the numerical value perhaps isn’t the best way to communicate the results, especially to a non-technical audience.
In addition to the difficulty in interpretting the coefficient values, the factor structure extracted from the organisation data does not align as neatly with the survey’s theme scores as the structure of the original 2009 factor analysis that was used to group the survey questions into themes. For example, the survey’s ‘learning and development’, ‘inclusion and fair treatment’ and ‘resource and workload’ themes have a complex relationship with the factor structure having theme and question level correlations with multiple factors.
The updated driver analysis has conducted two regression models, a cross-sectional and longitudinal model, to help fully explore the relationship between survey themes/factors and levels of employee engagement. Table 5 shows the standardised coefficients from both regression models. An illustrative ‘combined’ or ‘overall’ strength has been calculated by re-scaling both sets of cofficients from 0 to 1 and summing these. Those factors with an overall strength of 1.5 or greater are assigned as having a ‘strong’ association with levels of employee engagement, those factors with an overall strength of 1.0 to 1.49 are assigned as having a ‘moderate’ association with levels of employee engagement, those with and overall strength of 0.5 to 0.99 are assigned as having a ‘weak’ assocation with levels of employee engagement, and those with an overall strength of less than 0.5 are assigned as having a ‘limited’ or no association with levels of employee engagement.
Code
drivers_coefs |>
dplyr::select(term, inyr_std_est = std_estimate) |>
dplyr::left_join(
drivers_chg_coefs |>
dplyr::select(term, chg_std_est = std_estimate),
by = "term"
) |>
dplyr::filter(term != "(Intercept)") |>
dplyr::mutate(
rs_inyr = round(scales::rescale(inyr_std_est), 2),
rs_chg = round(scales::rescale(chg_std_est), 2),
overall_strength = (rs_inyr + rs_chg),
strength_label = dplyr::case_when(
overall_strength >= 1.5 ~ "Strong",
overall_strength >= 1.0 ~ "Moderate",
overall_strength > 0.5 ~ "Weak",
TRUE ~ "Limited/none"
),
across(c(inyr_std_est, chg_std_est), ~scales::number(.x, 0.01))
) |>
dplyr::select(
term, inyr_std_est, chg_std_est, rs_inyr, rs_chg, overall_strength,
strength_label
) |>
knitr::kable(
col.names = c(
"Factor", "Cross-section coefficient", "Longitudinal coefficient",
"Re-scaled cross-section coefficient",
"Re-scaled longitudinal coefficient",
"Combined re-scaled coefficients", "Strength of association"
),
align = c("lrrrrrl"),
)| Factor | Cross-section coefficient | Longitudinal coefficient | Re-scaled cross-section coefficient | Re-scaled longitudinal coefficient | Combined re-scaled coefficients | Strength of association |
|---|---|---|---|---|---|---|
| f1_management | 0.34 | 0.53 | 0.66 | 0.91 | 1.57 | Strong |
| f2_leadership | 0.52 | 0.59 | 1.00 | 1.00 | 2.00 | Strong |
| f3_work | 0.48 | 0.40 | 0.93 | 0.70 | 1.63 | Strong |
| f4_workload | 0.26 | 0.33 | 0.50 | 0.58 | 1.08 | Moderate |
| f5_pay | 0.16 | 0.23 | 0.32 | 0.41 | 0.73 | Weak |
| f6_objectives | 0.24 | 0.31 | 0.47 | 0.55 | 1.02 | Moderate |
| f7_career | 0.15 | 0.29 | 0.31 | 0.52 | 0.83 | Weak |
| f8_teamwork | 0.08 | 0.14 | 0.18 | 0.28 | 0.46 | Limited/none |
| f9_feedback | -0.01 | -0.03 | 0.00 | 0.00 | 0.00 | Limited/none |
While Table 5 assigns some ‘strength’ labels to the factors, how do these relate back to the survey themes - the actual measures that users of the survey data see? To communicate this, I’ve adapted the framework diagram in Figure 1 to include the results of the factor analysis. Figure 6 uses the correlations from Figure 5 and the ‘combined’ coefficient scores in Table 5 to demonstrate the relationship between the theme scores, the factors (which for non-technical audiences I’ve labelled ‘engagement drivers’) and the engagement index.
While the factor analysis was set up to extract nine factors, in Figure 6 I have only included the first 8 factors, the ‘feedback’ factor has been excluded for a number of reasons:
- the factor does not have strong correlation with any of the nine main survey themes;
- the questions with the greatest loadings on this factor load more strongly on other factors;
- in the cross-sectional regression model the factor does not have a statistically significant coefficient and has a very small coefficient in the longitudinal regression model; and,
- the factor has an eigenvalue of less than 1, accounting for only a very small ammount of the total variance in the dataset (<2%).
The arrows between the themes and factors show both the dominant correlations (those greater than 0.5) as well as some of the more moderate ones (those greater than or equal to 0.4), the arrows are dual-headed to indicate that the themes (and their consitutent questions) and the factors are in-effect two different ways of looking at the same information. The arrows between the factors and the employee engagement index represent the coefficients from the regression model and are a simple arrow flowing from the factor to the engagement index, to imply that by taking action on the areas covered by the factors should have an impact on the engagement index4. The thickness of each arrow is proportionate to the relative size of the correlations and coefficients.
Based on Table 5 and Figure 6 the themes have been assigned to one of three levels:
- Strong association: themes connected to the factors with the combined cofficients above 1.5, namely the ‘my manager’, ‘leadership and managing change’ and ‘my work’ themes since these are closely associated with ‘management’, ‘leadership’ and ‘work’ factors (respectively).
- Moderate association: themes connected to factors with a combined coefficient between 1.0 and 1.5, namely the ‘resources and workload’ and ‘organisational objectives and purpose’ themes which are related to factors 4 and 6 respectively. The ‘my team’ and ‘learning and development’ themes are also included, even though their ‘direct’ factors (factor 8 and factor 7 respectively) have a weak or limited effect on employee engagement (combined coefficient of less than 1). In the case of ‘my team’, this theme has a stronger correlation with the ‘management’ factor than with the specific ‘teamwork’ factor. In the case of ‘learning and development’, while this theme’s strongest relationship is with the ‘career’ factor, it aslo has relationships with three other themes (‘management’ and ‘work’ which have a strong association, and ‘workload’ which has a moderate association).
- Weak association: the remaining theme, ‘pay and benefits’, is only closely related to a single factor (factor 5) which has a combined coefficient less than 1.
References
Cabinet Office. 2014. “Technical Guide.” Civil Service People Survey: 2014 Results - GOV.UK. https://www.gov.uk/government/publications/civil-service-people-survey-2014-results.
———. 2016. “Cabinet Office: Civil Service People Survey 2016 - GOV.UK.” https://www.gov.uk/government/publications/cabinet-office-civil-service-people-survey-2016.
Footnotes
See the section below for a brief introduction to factor analysis↩︎
Questionnaire changes mean that some questions are not present in all years, this analysis has focussed only on those questions which exist in all 16 years of the data. This has been done to ensure the largest possible and most consistent dataset it used and no accommodations for missing data need to be made. As a result only 45 questions have been included in the factor analysis.↩︎
The engagement index ranges from 0 to 100 whereas the factor scores range from -5.96 to +5.08, the simple coefficients from the regression model are therefore not easy to interpret. The beta coefficients, standardise the variance in each variable of the model, as a result these coefficients represent the effect a one standard-deviation change in the the factor scores will have on the engagement index (in standard deviations of the engagement index).↩︎
Personally I think there is likely that there is some sort of feedback-loop in play between levels of employee engagement and opinions and attitudes about individuals’ experiences work: that being in a state of high employee engagement is likely to make you view workplace experiences more positively and being in a low state of employee engagement may make you view experiences more negatively. And/or being in a team/organisation that has high or low levels of employee engagement is likely to influence how you view your experiences. However, this is difficult to analyse based on the publically available data.↩︎